When it comes to innovation using AI & Data Science, there is 2 ways to go about, in the way I see it: Automation & Customer Satisfaction
Today I am going to focus on the Automation part and next week we are going to talk about Customers Satisfaction.
Automation is the process by which we are going to improve the cost efficiency of our business. Which means we want to do more while spending less money.
Automation is a process. Try to go too fast and you might end up failing along the way. And too slow and you might go out of business because the competition has become more efficient at getting the job done than you.
But fortunately this process can be mapped using the 7 Stages Of Automation. Those stages allow you to first assess your current level of maturity. In order to have an objective view of where you are currently. To then know clearly where you need to go, with a clear linear path toward improving efficiently.
So let’s dive into each of those stages individually
Stage 1 – Manual
When it comes to automation, we really have 2 ways to go about it: the Linear and the Exponential ways.
The Linear way of automating fit perfectly the 7 Stages process. Because at each stage we are focusing on getting the job done, while each time doing a bit better and faster.
The Exponential way is more long term oriented. Where we focus on where we want to go and what we want to achieve over the long term while sacrificing short-term results.
When we look at those 2 strategies, one beat the other on the short term and the other on the long term:
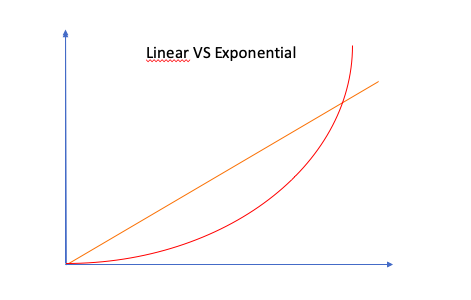
The primary reason behind this difference over the long-term is directly correlated to the idea of technical debt.
In the Exponential way you are doing things right, right from the beginning, by making sure very little technical debts are going to be built.
In the Linear way, you are just getting the job done now, and focusing on solving the issue that technical debt may rise later, when the problem actually comes up. Which over the long term is penalising.
This is a matter of choice, but this choice will have an immediate impact on the vision and innovation strategy that you are going to put in place.
In the Exponential way, you are not going to focus a lot on the manual stage of automation. And directly think the process as it should be in the end and start right from the second stage.
This is more a 0 to perfect mindset, which can be very dangerous. Because you might choose a direction right from the beginning, think this is the way to go. But only to realise, 5 to 10 years down the road, that’s actually it wasn’t the good way to go.
So really be careful it choosing to go for the exponential way. Take the time to put everything down.
It is actually more safe to choose the Linear way. Because even if you might not get the potential highest result that the exponential way give you at least you are constantly moving forward while making sure you are getting somewhere.
This is where the Manual Stage comes. If you choose the Linear way, you are going to follow this 7 Stages Process, and starting with the Manual Stage.
In this stage you are focusing on getting the job done. What needs to be done? How many employees? What skills are required? …
You are figuring out everything and making sure everything is taken care of in the simplest and most efficient manner.
This stage is actually more important than most people might think. Because you will spend a lot of time trying things, testing idea on how to improve your process.
And those who actually skip this stage, or don’t spend enough time in it, will start to automate processes that are not efficient and likely to change in the future. Which will cost more money to change everything later.
So spend time in this stage, figuring out what work and what doesn’t. Testing ideas and process. Until you find an efficient process that your organisation is comfortable doing.
And even if you are choosing the Exponential way, once you’ve mapped your vision of what you want to build, it’s important to test it on a smaller scale.
To do that, and actually compensate the flaws of the Exponential way, use the concept of MVP (Minimum Viable Product) developed in lean startup. Which state that you want to build quickly the first version of a product in order to get feedback from the user as soon as possible in the development process.
And this is actually what you want to do. You want to build a system / product that answers your needs over the long term. So adopting an iterative approach to do that will drastically reduce the risks of failing along the way.
So wrap things up on the Manual Stage, we are getting the job done. Testing process, finding what work and what doesn’t. Until we found a comfortable way of doing things which is efficient to us and deliver the most value to our customers.
Stage 2 – Scripted
Here you are, you’ve tested your processes, find what work and what doesn’t. You’ve built momentum and now you reach a plateau of performance. Where you are able to get done everything that need to get done and most employee in your organisation know what they should do and how they should to it.
Now it’s time to systematise and standardise everything you’ve established so far. By identifying right now the known and the unknown. What people are doing that they are told to do and what they are doing, which they are not told to do, but they know this is how they should do this if they want to get things done.
At the end of the manual stage, the knowledge of the process is still abstract. It’s in the head of everybody. Every employees kind of know the processes. They have learnt it through experience and no one really have to tell them.
So in the Scripted Stage, you want to clarify all of this. You want to enter in the head of everyone to figure out what they are doing, what they are not doing, why they are doing it and why they are not doing it. Both individually and as a group.
This stage is a 4 steps process:
- Clarify
- Discuss
- Systematise and standardise
- Build Scripts
Once the clarification is done. You need to discuss it with the team. To ideate and maybe find ways you can improve it using the feedback of everybody.
This has 2 really important goal. The first one is to actually improve upon what has been done until now, to be more efficient and productive. And the second is to make people aware and on the same page.
In a lot of organisation, people know what they are doing but don’t know what other people are doing. Which can create a lot of friction and duplicate works. Therefore, reducing the cost efficiency of the organisation.
So this is really important. At this stage, you want your processes to be clear and known by all employees involve in those processes.
The discussion step should not be overlooked. Has it helped to make things clear in the mind of everybody, so everyone is on the same page. This is going to create synergy within your teams and boost their productivity.
Then the idea is to Systematise and Standardise. Now it’s time to agree on the processes with everyone. To define how we do things, who is responsible for what, what happens when …
Write documentation, presentation, and so on to make sure your knowledge base is recorded.
And the final step of the stage is to Build Scripts. But building script doesn’t necessarily mean building program to do the job. Because at this stage of development, most of your processes are going to be very difficult to automate using programs. You can also build script for people to follow in each situation.
So first you build the script and procedures that define the processes you’ve clarified earlier. So everyone knows what and how they should do what they do.
Something important to keep in the mind of your employees, those procedures are not set in stone. They are going to evolve overtime as you get their feedbacks. You don’t want to tell people how to do their job; you want them to tell you how to do it better. This is an important distinction that you need to make sure is clear in the mind of all your collaborators.
Finally, now that you have your procedures. Which one can you program? Or which part can you build code that actually gets the job done?
Now we are starting our digital automation. Starting using developers to automate part of the jobs here and there. We literally build code scripts that can be executed.
Bring together your business teams and your development teams. Let them work together on the procedures to figure out what can be automated and what cannot in your current state of developments.
And for the things that you cannot automate right now. Maybe you can try to deconstruct them into subparts that can be automated or partially automated.
The goal here is not to do complex programming, but rather focus on what is easily automatable and for the reset being sure the processes are clear, systematise and known by everyone.
Stage 3 – Tooled
Now the interesting part starts, because this is where the biggest digitalisation transition your organisation while ever face is.
In this stage we want to get as much as possible our processes completely digitalised. By first consolidate our data into databases and then build applications for the business to use those data and execute their job.
So 2 projects have to be performed in parallel:
- Data digitalisation and centralisation for easy access in the future
- Applications building for the business with good user experience that make the processes easier to execute
So let’s take those 2 parts individually, shall we.
- Data digitalisation and centralisation
In the information age, data is at the heart of everything. A strong, well organise database, that anyone can easily access with the right authorisation is the biggest asset your company can have.
So during this phase, you need to assess all data that you are collecting, using and generating. And once this assessment is done, you need to make sure EVERYTHING is stored and that you keep a proper history of every data that ever passes through your systems of information.
Why that? You don’t know what the future is going to be, and what level of automation and innovation you will want to have in the future. But if ever you want to automate and innovate using AI and Data Science, which become more and more a requirement rather than just a nice to have, you will need as much historical data as you can.
But data storage can be costly. So the idea is not to store everything forever. It’s just that as a first step here, you want to put in place the system in a way that is designed to record and store everything over the long term. To then assess, when you start struggling with data storage capacities, the relevance of those data. In order to take one of those decisions:
- Pay for more data storage because you consider your data valuable and you want to keep them
- Determine which data you can delete, or just how far into the past you want to keep those data. So when they reach those points, they are deleted automatically.
Your final decision will most likely be a mixture of those two decisions depending on each type of data you are facing.
To make those decisions wisely, you need 2 things. The first things is to be clear on the long-term vision you have for your organisation (5-10 years down the road, where do you want to go). And then you need data experts, that are going to tell you what you need to keep or not in order to reach your long-terms innovation goals.
That way you make sure you are not shooting yourself in the foot by accepting to delete data you may need in the future.
As a general rule, keep everything. But depending on your resources, it can be a good idea to periodically assess the relevance of the data you are keeping track of in order to reduce the storage cost of those data if this becomes an issue.
- Applications building with nice user experience
Those Applications should partially or totally embed the business processes. They can come in a form desktop application or web application that can be accessed anywhere using a browser.
The key here is going to be the design of those applications. Regardless if you are going to build those applications by yourself or you are going to pay external resources to build them. The UX (User Experience) is what matter the most.
The reason is simple. You are going to transform the way your business is operating. So they are going to be the primary factor that will dictate if the digitalisation of your processes is going to be successful or not.
So there is a deep need to show them that those applications you are building are going to improve the way they work. That they are going to help them be more productive and efficient in the way they do their day-to-day job.
And this will be dictate primarily by the design of those applications. As a result, this is really important that the business take part in the design phase, so they feel part of the process and that we are not forcing them into something new.
With the help of UX Designers, you can go through the Design Thinking Method in order to achieve this result. This method come in 5 phases that are repeated over and over until the business is satisfied with the solution that we are giving them.
Those 5 phases are:
- Empathise – What is the actual experience of the user?
- Define – What are the different issues and problem they are facing?
- Ideate – Sessions of Brainstorming to find and organise solutions
- Prototype – Design first version of the application (MVP Philosophy)
- Test – Make the user test the Prototype and give you the first feedbacks
With this process in mind and a solid data management system put in place, you make sure you are moving in the right direction to maximise your chances of success in your digitalisation transition.
Stage 4 – Automated
Building a rule based system that automate the systematic part of the processes while easing the discretionary parts… Lot of big words, but this is what this stage is about. So let’s define all of that.
- Systematic VS Discretionary part of a process
Regardless of the processes your business teams are executing, the task that they perform can be classified as Systematic tasks or Discretionary tasks.
The Systematic tasks are the tasks that can be easily defined by rules. There is no interpretation, there is no guess, those tasks have to be performed in a certain way in order to get the expected result.
On the opposite side the Discretionary tasks, relies on the interpretation and the experience of the person who is performing the task. There is no black and white rules that can be applied, the decisions the employees have to take depend on the experience they have accumulated over time.
But even if the definition of what is a discretionary task and what is a systematic task are clear. In reality, it can be sometime difficult to distinguish between those two.
The reason for that is that “Task” is a broad word. What we think we can call a task might often be a complex mixture of different action, which some are systematic and some are discretionary.
- Classify the processes Tasks
Due to this complexity of defining what is what, we first need to go through the process of iteratively classify to sort this out.
This is a process of ideation you need to go through with your business and developers teams. I added the developer because they are the one that are going to ask the question to know if the task can be programed just using rules or not. And therefore identifying the systematic from the discretionary.
So in order to really enter into the head of the business and understand as much in details how they do what they do, we are going to classify each task into 2 categories, which might not be the one you expect:
- Systematic Tasks
- Complex Tasks
The reason I use complex task instead of discretionary tasks is because we actually don’t really know if this is a discretionary task or not. And this where the iterative process beginning in order to stimulating creativity in the room.
The process is as follow:
- Collect all the task that the business is doing
- Classify them into those 2 categories
- Then focus on the complex task and for each of them deconstruct them into smaller tasks
- Then classify the smaller task using the 2 categories
- And keep doing that until you find the TRUE discretionary task that only the business can perform and the developers have no ideas how to build a rule based system to do it.
That way you are forcing people to think deeply into what they are doing and stimulate creativity in order to find systematic solutions. And by doing so, you avoid the trap that most organisation fall into, which is to build AI or Data Science model to solve tasks that are actually systematic.
And this is a big issue because on a systematic task no AI or Data Science model will do better than a rule based system. Most likely than not, they will do worse.
So by following this process, you are making sure you never make this mistake.
- Building and deploying your systematic system
Now you have identified the tasks you want to automate using rules based system. You can build your system in 2 different ways:
- Simply by programming it
- Using RPA (Robotic Process Automation) tools
RPA are a good way to deal with systematic systems. They are, by design, built to automate business processes by focusing on basic task. But can perform complex process when well programmed by deploying 100s or 1000s of robots that are going to work together.
But as good as those tools are, you need to mitigate the cost of them compare to just having a developer build the system, which, if the classification and decomposition of task has been done properly, could relatively done easily.
By choosing to use your developer to do it, you ensure that in the future you’ll have total control over what you’ve built rather than depending on some 3rd party tool. Those tools have a recurrent cost, where the cost of developing it by yourself is an investment that will pay for it over time.
This is a choice to make depending on your available resources and whether or not you can hire more people for that. Also, the fact that if development is not what your company does, you may even consider outsourcing the development of your systematic system.
- Take time to get feedback and improve
Final point, TAKE YOUR TIME in this stage and don’t rush to the next stage. Because as the culture of systematisation will spread into your organisation, business and developers teams will start to get more and more idea on how to make things more and more systematics.
Especially after the implementation of the first version of your system, feedback will rise. And those feedbacks a really important to improve continuously the system.
So take the time to build the process to smoothly collecting those feedbacks and ideas, then discuss and rank them by priority in order to take action and improve efficiently.
This is a whole new process that needs to be built due to the culture evolution that is happening in your organisation. That’s why it’s important to take the time to build this process. Making sure everyone is on board with it and that everything runs smoothly.
For this process, you can also apply what you’ve already done in this stage for other processes, in order to automate all the systematic part as well.
To conclude on this stage, for a lot of organisation this level of automation might be enough and the need to go further to automate discretionary task might not be worth the cost of doing so.
The primary goal of automation is to promote long-term growth by removing scalability issue. If beyond this point you are not facing those kinds of issues, you may consider just consolidating what you’ve already done rather than keep innovating in that direction. Again, that’s a choice you need to make depending on your circumstances and the vision you have for your organisation in the future.
Stage 5 – Auto-Trigger Assisted
Now that we have automated the systematic task and identify the one that are discretionary, it’s time to focus on the Workflow. Because having a lot of script that are executed independently, or just having a few scripts that work together is not enough.
What we want to build in this stage is a fully automated pipeline where the only breaking points are the discretionary part of the process. So let’s dive into the automation of the automation workflow and see how AI & Data Science can start to be used in order to soften the transition between the systematic tasks and the discretionary ones.
- Automation of the Automation Workflow
The idea is to identify the chain of events that are going to connect each task together.
We want to create a cascade of event which will go from one event, propagate through all the systematic tasks to reach the first discretionary task.
Currently, the automation will only go as far as the first discretionary task comes up, but in the next stage we are going to see how to overcome this issue using AI & Data Science.
In order to create this cascade of event we need a few things:
- The list of your automation workflows that you need to automate
- Identify the main external events that can trigger the whole workflow
- Defining the workflow
- Connecting the tasks together
Getting the list of your workflows shouldn’t be that hard if you followed your the different stage until now. Your processes are clear and define. So you will probably have a pretty good idea of the different workflow you need to build in order to accomplish those processes.
Then we need to identify of why this workflow exists in the first place, by establishing the main events that are going to trigger the different workflows we have. For instance, if this is just a job that should run periodically, the main event is going to be simple – Once we reach the define period, launch the process. But more generally, you can have 3 types of main events:
- Scheduled event – Things are scheduled to run in advance
- Application based event – When something special happens on the application level, the event is detected
- Human based event – Someone is going to trigger the event
Once those events are defined, we now need to define the actual workflow that is going to be performed once this event is trigger.
So for each of those events, list of all tasks that need to be performed, systematic as well as discretionary. Once you have it, establish the order in which those tasks need to be performed, the actual workflow.
During this phase you also need to identify all the conditions. The conditions are the rule that will trigger one task rather than another within the workflow.
Most likely, all the tasks you’ve listed don’t have to be executed every time the event happens. They have to be executed if certain conditions are met. So it’s important to take the time to identify those conditions, and depending on whether or not those conditions are met, what is the tasks that need to be performed.
So your workflow is going to look something like that, but with a lot more tasks:
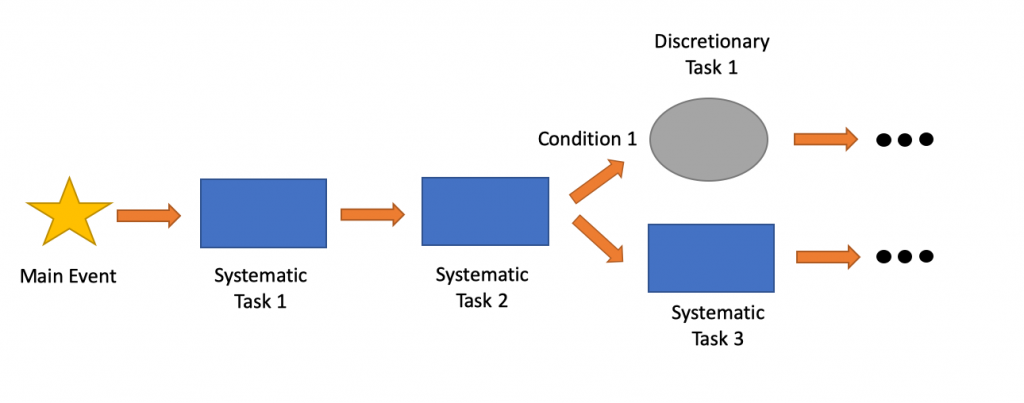
Then the last step of the automation of the automation workflow is to connect each task together.
First, we want to clarify the inputs and outputs of each task as we have automated them until now. What each systematic script or program need in input in order to run successfully. And what are the outputs that those scripts and program are generated. Just a simple assessment of where we are currently.
Then we are going to match the outputs of each task with the inputs of the following. To identify the difference. Those differences are going to be the first issues to solve in order to connect properly the workflow.
So by listing them exhaustively, you can put your team of developers on it. And start working on the standardisation of the outputs-inputs schemas.
Once this is done, there is one more last step to connect everything together. Establishing the underlying events that should trigger each task in those processes.
May be most of your task can just be connected together, but some will need something more. And because of that, you may need to put them on standby waiting for this event. So this is important to identify what are those breaking point in the workflow and how you are going to manage them.
Now you have it, your whole automation of the automation workflow is functional and ready to go.
- How AI and Data Science will help this process
As I said earlier, the automated workflow will go as far as the first discretionary task appears. So even if the human intervention is required at this point, we want to easy the process to the best of our ability.
We want the human action to be focused and efficient. This is where AI and Data Science are showing up first the first time.
I want to take a minute to remind something. Until now we didn’t use AI or Data Science. That’s because they just didn’t have their place their. Those skills and technology bring value on complex high-level task. And until now, this wasn’t our focus.
I see too much people wanted to do AI and Data Science because it’s the most popular thing to do. But really, until you reach the second part of the 5th stage of the 7 Stages Of Automation, this is counterproductive to even think about doing AI and Data Science.
But here we are, second part of the 5th Stage of the 7 Stages of Automation. Now AI & Data Science can bring a lot of added value.
So depending on the actual discretionary task that needs to be performed, the way we can ease the process here come primarily three forms:
- Visualization
- Recommendation system
- Scoring System
In this stage we really want to keep things simple, where in the next stage, we will take things to the next level. And those three ways of going about doing AI & Data Science does just that.
Visualization, by providing visual insight about the subject that needs to be performed during this discretionary task, we can help the business to make quicker and more efficient decision. Where there is basic visualization, AI & Data Science can provide deeper insight by either using machine learning or statistical analysis.
Recommendation System. Simply put, having a system the recommend which action might be the best to perform could be very handy. But the value of that goes beyond just the recommendation.
By doing so, you are laying down the bricks for future higher automation, where your algorithm will be able to learn from what it though was the best action to perform and what the actual business decision final was.
If you identify some discretionary tasks that you wish to automate in the future, starting with some kind of recommendation system and building datasets for training purposes is a very good way to go about it.
And finally, the Scoring System. The idea here is to measure and rank elements. We can, for instance, score the quality or the relevance of certain items have, and present them in the order that seems to be the most relevant for the business.
For instance, if you have a list of alerts of potential fraudulent behaviors. The business needs to manually go through those alerts to make to filter out the valid from the not valid ones.
So what the scoring system does is ranking the alerts, in a way that the ones that are the most suspicious come up on top of the list, and the ones that are the least suspicious come last. This ensures that the riskier ones are handled as quickly as possible.
Here you have it, you have completely automated your workflow and made your first steps into innovating using AI & Data Science. Let’s now take things to the next level.
Stage 6 – Intelligence
Finally, let’s more toward making our system intelligent. But what do you need to get there?
Actually, not much. You have put the working in the previous stages to make sure everything is set up the right way. Your processes are clear and the systematic parts are completely automated.
The only parts that are left to automate are the discretionary parts. And this is the exact focus of this stage. How do we take our automated systematic system to a fully automated intelligent system? Let’s figure it out!
- Building datasets
The first things to do is to record. We want to monitor the discretionary processes in the most details possible. In order to generate as much data as possible on what’s going on in this discretionary process and build insight on the decision process of the business.
Data that we would like to record may vary a lot from one discretionary task to another, but there is some general guideline that we can follow as a starting line.
Here is a list of the data that you may want to record:
- Inputs and outputs of the system
- The action that has been performed by the business within the task
- Some explaination or added context regarding the decision that has been taken
First of all, they are the inputs and outputs. What are the informations that the business is receiving and what are the decision or resulting data that the business is producing.
This at it’s core is a very important dataset to build. Because if the discretionary process that is executed is simple enough, you could use that to build and train and AI model (Supervised or Reinforcement Learning Model) to learn the behaviors of the business in order to automate it.
Then we have the actions that have been performed by the person in charge within the task. This is when the discretionary task is so complex that we need deeper insight on what’s happen.
There is a warning here. Because maybe this task is a complex task constituted of sub task that some may be systematic and some discretionary. So if that’s the case, this means that the deconstruction done in the previous stage of the task hasn’t been done properly.
But maybe that’s not the case, and the task is actually a complex discretionary task. In that case, we need to understand as deeply as possible what the decision process that the person performing the task goes through.
To do that, we are going to record every action possible that the person is doing. A good way to go about it is to design that application where the person is performing the task in a way that every action is handling digitally through the application. And if, as I advice earlier, you’ve embedded the whole business process inside application, that should not be that difficult.
And finally, we want some explanation of why this decision has been taken or why the result is the way it is. We do that by adding context and description at the moment of validation of the task, once the person has done it. It could be a short form, for instance, that the collaborator complete before sending the result or decision.
But there a few guide line regarding data quality that need to be followed to ease the data science and ai process in the future:
- Try to avoid description area where the person can write everything they want. You can add it as a bonus information, but keep in mind that most of this information will not be usable in the future.
- Focus on drop-down and check boxes, where the answers are already built. This will ensure you have quality data in your database.
- Leave another option with a blank area to manually add what is the answer. This will not been use by data scientist but it’s to see how the current data capture is efficient at taking in all answers. And if not, you will have a track record of other answer that are given. That way you will be able to optimise your form overtime to perfectly fit each discretionary process.
So to sum up on building your database to automate your discretionary processes. Keep track of the inputs and outputs. Identify the underlying action that the person performing the action is doing. And finally, add context to the results or decision that has been taken.
- Training your models
Now that you have all the data needed, it’s time to build models.
The first things you need to do is going to define what is your baseline performance. It’s can be either what the business is doing or a simple model to start with.
The idea here is not really to focus on the model. But focusing on how you are going to evaluate the quality and performance of the model. How do you know the decision that has been taken is good or not? How do you define the quality of the result rendered?
This is the basic establishment of the KPI (Key Performance Indicator).
If necessary, you may need to build tool or infrastructure in order to measure the actual result of the business actions.
Then you start measuring objectively the performance or quality of what the business is doing. And therefore get your very first baseline.
A baseline is a reference point that we are going to use to build models in the future. AI model development is a never-ending process. Especially in the field of AI where progresses are made constantly. But that’s not only that, the more time your data scientist spend to analyse, understand and prepare data, the better the model is going to be.
But in the business environment, we can’t spend an unlimited amount of resources for an unlimited amount of time. That’s where the use of baseline its require. Because we are going to focus on building iteratively models and each time with the target of beating the previous baseline.
If the new model we built beat the baseline line, it becomes the new baseline. But we don’t throw the previous one away. It’s important to keeping track of the performance of each iteration of a model. To ensure 2 things:
- That the improvement we made is actually one over the long term
- If the model for some reason starts performing less well than we expect in production, we want to have backups to use when that happens.
You basically follow the same iterative process that the lean startups are follows using the MVP (Minimum Viable Product) philosophy. Where you develop your model with a certain amount of time restriction. At the end, you measure the performance. To then decide or not to continue.
At each iteration you can face 3 cases
- The performance is significantly better than last time
- The performance is better but not really significate
- The performance is not better that the baseline
Over time, it’s going to be more and more difficult to improve the performance of your models. And at some point you will have to mitigate the cost of continuing to improve the model performance and the actual benefit you will get in return.
That’s why it’s important to have a realistic expectation of what the model performance should be and once you reach that point take adequate decision. But that’s a topic for another day. So let’s move on.
- Risk Mitigation – Transitioning toward intelligent system
At first the idea is to replace what the business does. You want to build your model and compare their performance against the ones of the business during a significant amount of time. To determinate if the model is consistent and reliable.
Something that you need to keep in mind is that AI & Data Science model are Statistical and Probabilistic models. Which means they are an approximation of reality and not reality itself.
As a consequence, those models are going to make mistakes from time to time. As human do, we call that human error. But if a human makes an error, we know who to blame for it. On the opposite side, if the model makes a mistake, who are you going to blame for it? The Developers? The Data Scientist?
You can’t blame anyone for it. As I said, the model is an approximation of reality and it’s going to make mistakes from time to time. So this is a risk you need to mitigate.
That’s why it’s important to first monitor the model and establish a performance target. This performance target will be the best fit for you regarding your risk mitigation. Where you can say, at this performance level I am confident enough to delegate this discretionary process to the model.
And by following this process of risk mitigation against model performance, you will be able to progressively move toward a more and more intelligent system.
But if in some cases the risk is too big for you to delegate to a model. You’ve found where the Most Valuable Tasks in your organisation are. And this is where your employees need to spend the most time on, in order to make sure those tasks are done properly. Those tasks require quality job rather than the speed given by automation.
Stage 7 – Global Intelligence
This stage is simply the natural evolution of the last stage. Where everything that needs to be automated is automated, you have a complete intelligent system. The high-risk-high-value tasks are the only one that the business is focusing on. Which makes your process highly efficient and secure.
The remaining employees are focusing on monitoring the system and making sure everything is going as expected. While your R&D departments work actively at improving the efficiency of the overall process and build better and more accurate models.
Let’s dive into each of those parts.
- Business focusing on High Value High Risk Tasks
The definition of a well manage organisation is when each resources are allocated where it can provide the most value for the company. This ensures a fantastic cost efficiency, where the return on investment put in those resources brings the most benefits.
And by reaching this point of automation, you’ve been able to do just that. Your business teams have now the time to focus on the task that brings the most value for the organisation and on the task which are the most risk sensitive.
The high-value-high-risks tasks are the one that make the difference between succeeding and failing in business. Unfortunately, most business doesn’t have the luxury to spend as much time as necessary on those tasks, therefore increasing their risk of failure.
But that’s not your case. Now that you’ve automated all the other task you are in a position to spend the necessary time on that to ensure everything is going well and is going to continue to go well.
You have effectively eliminated this risk factor from your organisation.
Well Done!!!!
- Monitoring the system
But if you want to be able to stay safe over the long-term, it’s important to monitor rigorously your system to make sure everything is running as expected.
We are talking here about 2 types of monitoring:
- Technical Monitoring
- Qualitative Monitoring
The technical monitoring is simply making sure codes / jobs are running well, infrastructures are up and running. You are able to avoid as much downtime as possible, and so on.
Then the qualitative monitoring is where you check that all systematic and discretionary tasks are actually doing what they are supposed to do. Like for instance, checking that your model on discretionary tasks are not drifting in performance and stay relevant.
But this qualitative monitoring is also used to periodically assess each task in the process to make sure they are still relevant. And if not, you need to identify what are the evolution that the process is going through. To then, update your system.
- Keep improving the efficiency and accuracy of the overall system
Ok everything is now under control, working and being monitored. We can take a break and enjoy, right? Hummmm … not sure you want to do that.
The business game is what we call an Infinite Game. It never ends. And the winner is the one that stays in business the longest.
If you want to make sure your competitor never outgrow you, you need to constantly work on improving the efficiency and the accuracy of the overall system.
Analyse each process as they are built and find ways to make them better and more efficient. In order to make the automation process more effective, easier to maintain over time and overall easier to automate.
Once this is done, go through all your discretionary tasks, analyse your models that are performing those tasks. Check if new technologies of methodologies have been developed recently that could do a better job than what you are currently using. And so on…
Do it again and again and again … this is a never-ending process of improvement, staying updated about the recent news and state-of-the-art models that are built. In order to always keep learning and growing, and making sure your organisation adapt and evolve as fast as the world do.
- Google Example
I want to finish by taking the example of Google. Which is probably one of the most known company, when it comes to AI & Data Science developement.
This is the only company I know of that have reach this kind of level of automation. Where they have their search engine that can learn and grow by itself. The R&D teams are working on making this system better and more efficient. To handle more and more complex task with always more and more accuracy. And To face the scalability issues of searching the worldwide wed that is constantly growing at faster and faster rate.
So that’s no wonder why they are leading the way when it comes to AI and Data Science development. Thanks to their level of automation, they are able to allocate their resources toward the most valuable tasks the company can perform. While in the mid-time, their competitors are still struggling to get the job done.
Conclusion
Automation is a long-term process that takes time to get done the right way. But this is a time well spent that will ensure the long-term success of your organisation.
We saw that we first need to build our Processes (Stage 1 – Manual), then making sure they are clear and know by everyone to the point where we can build Scripts (Stage 2 – Scripted). One that is done, we move on to the digitalisation of the business process by embedded them into Desktop or Web Applications (Stage 3 – Tooled). Then we can start automating by starting with to identify the Systematic and Discretionary tasks, so we can focus on automating the Systematic first (Stage 4 – Automated). Now it’s time to focus on Automating the Automation Workflow by identifying the different events that bring together all the Systematic and Discretionary tasks (Stage 5 – Auto-Trigger Assisted). At this point all the systematic part of our processes is handled, we can now focus on the discretionary parts using AI & Data Science to Build Intelligent Models (Stage 6 – Intelligent). And Finally we saw what it takes to Stay At The Top once we reach the highest level of automation (Stage 7 – Global Intelligence).
Congratulation if you’ve been able to read through all of this. It was a bit longer than expected, but I think this gives a clear overview of the overall process.
Thanks for reading and see you next time!